В этой статье мы узнаем, что такое веб-таблицы и как с ними работать в Selenium.
Подпишитесь на наш ТЕЛЕГРАМ КАНАЛ ПО АВТОМАТИЗАЦИИ ТЕСТИРОВАНИЯ
Содержание:
- Что такое веб-таблица в Selenium?
- Чтение HTML веб-таблицы
- Как работать с веб-таблицами в Selenium
- Доступ к вложенным таблицам
- Использование атрибутов в качестве предикатов
- Использование Inspect Element для доступа к таблицам в Selenium
Что такое веб-таблица в Selenium?
Веб-таблица (web table) – это веб-элемент, используемый для представления данных или информации в виде таблицы. Отображаемые данные или информация могут быть как статическими, так и динамическими. Доступ к веб-таблице и её элементам можно получить с помощью WebElement функций и локаторов в Selenium. Типичным примером веб-таблицы могут служить спецификации товаров, отображаемые на платформе интернет-магазина.
Чтение HTML веб-таблицы
Бывают случаи, когда нам необходимо получить доступ к элементам (обычно текстам), находящимся внутри HTML-таблиц. Однако очень редко веб-дизайнер задает атрибут id или name для определенной ячейки таблицы. Поэтому мы не можем использовать привычные методы типа “By.id()”, “By.name()” или “By.cssSelector()”. В этом случае наиболее надежным вариантом является обращение к ним с помощью метода “By.xpath()”.
Как работать с веб-таблицами в Selenium
Рассмотрим приведенный ниже HTML-код для работы с веб-таблицами в Selenium.

Мы будем использовать XPath для получения внутреннего текста ячейки, содержащей текст “fourth cell”.
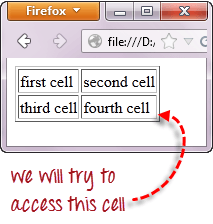
Шаг 1 – Установка родительского элемента (таблицы)
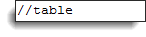
XPath локаторы в WebDriver всегда начинаются с двойной косой черты “//”, а затем следует родительский элемент. Поскольку в Selenium мы имеем дело с веб-таблицами, родительским элементом всегда должен быть тег <table>. Поэтому первая часть нашего Selenium XPath локатора таблиц должна начинаться с “//table”.
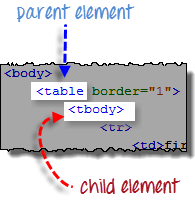
Шаг 2 – Добавление дочерних элементов
Элемент, расположенный непосредственно под <table> это <tbody> поэтому мы можем сказать, что <tbody> является дочерним элементом по отношению к <table>. Все дочерние элементы в XPath располагаются справа от родительского элемента, разделяясь одной косой чертой “/”, как показано ниже:

Шаг 3 – Добавление предикатов
Элемент <tbody> содержит две пары тегов <tr>. Мы можем сказать, что они являются дочерними элементами по отношению к <tbody>. Следовательно, тег <tbody> является родительским по отношению к обеим парам тегов <tr>.
Чтобы перейти к ячейке, содержащей текст “fourth cell” между двумя тегами <td>, мы должны сначала обратиться ко второй паре тегов <tr>. Если мы просто напишем “//table/tbody/tr”, то обратимся к первой паре тегов <tr>.
Как же тогда получить доступ ко второй паре <tr>? Ответ на этот вопрос заключается в использовании предикатов.
Предикаты – это числа или HTML-атрибуты, заключенные в пару квадратных скобок “[ ]”, которые отличают дочерний элемент от его “братьев и сестер”. Поскольку пара тегов <tr>, к которой нам нужно получить доступ, является второй, то в качестве предиката будем использовать конструкцию [2]:

Если мы не будем использовать какой-либо предикат, то XPath обратится к первой паре тегов, поэтому принципиальной разницы в использовании любого из этих кодов XPath нет:

Шаг 4 – Добавление последующих дочерних элементов с помощью предикатов
Следующий элемент, к которому нам необходимо получить доступ, – это вторая пара тегов <td>, где записан искомый текст. Применяя принципы, полученные в шагах 2 и 3, мы доработаем наш XPath-код, как показано ниже:

Теперь, когда у нас есть правильный локатор XPath, мы уже можем обратиться к нужной нам ячейке и получить её внутренний текст, используя приведенный ниже код. Предполагается, что приведенный выше HTML-код сохранен на диске C под именем “newhtml.html”.
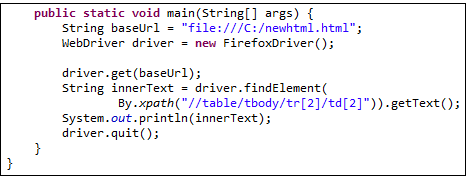
public static void main(String[] args) {
String baseUrl = "http://demo.guru99.com/test/write-xpath-table.html";
WebDriver driver = new FirefoxDriver();
driver.get(baseUrl);
String innerText = driver.findElement(
By.xpath("//table/tbody/tr[2]/td[2]")).getText();
System.out.println(innerText);
driver.quit();
}
}

Доступ к вложенным таблицам
Те же принципы, о которых говорилось выше, применимы и к вложенным таблицам. Вложенные таблицы – это таблицы, расположенные внутри другой таблицы. Пример показан ниже.


Для доступа к ячейке с текстом “4-5-6” мы так же оперируем понятиями “родительский/дочерний элемент” и “предикат” из предыдущего раздела. В итоге должен получиться следующий XPath-код:
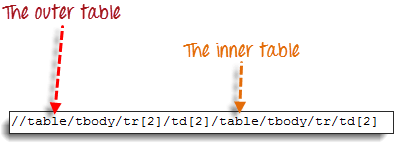
Приведенный ниже код WebDriver должен получить внутренний текст ячейки, к которой мы обращаемся.
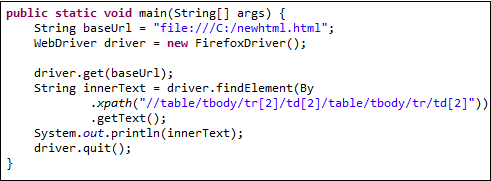
public static void main(String[] args) {
String baseUrl = "http://demo.guru99.com/test/accessing-nested-table.html";
WebDriver driver = new FirefoxDriver();
driver.get(baseUrl);
String innerText = driver.findElement(
By.xpath("//table/tbody/tr[2]/td[2]/table/tbody/tr/td[2]")).getText();
System.out.println(innerText);
driver.quit();
}
Приведенный ниже вывод в консоль подтверждает, что доступ к внутренней таблице был осуществлен успешно.

Использование атрибутов в качестве предикатов
Если элемент написан глубоко в HTML-коде, так что определить число, используемое для предиката, очень сложно, то вместо него можно использовать уникальный атрибут этого элемента.
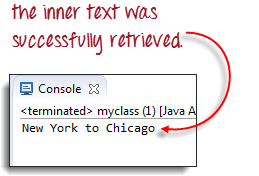
В приведенном ниже примере ячейка “New York to Chicago” находится глубоко в HTML-коде главной страницы Mercury Tours.
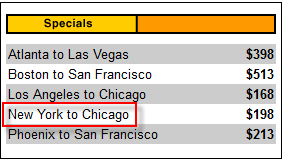

В данном случае в качестве предиката мы можем использовать уникальный атрибут таблицы (width=”270″). Атрибуты используются в качестве предикатов путем добавления к ним символа @. В приведенном примере ячейка “New York to Chicago” находится внутри первой пары тегов <td> в четвертой по счету паре <tr>, поэтому наш XPath должен выглядеть так, как показано ниже:

Помните, что когда мы помещаем код XPath в Java, то для двойных кавычек с обеих сторон от “270” следует использовать символ обратного слэша “\”, чтобы строковый аргумент By.xpath() не был преждевременно завершен.

Теперь мы готовы получить доступ к этой ячейке, используя приведенный ниже код:
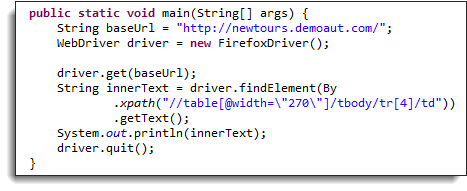
public static void main(String[] args) {
String baseUrl = "http://demo.guru99.com/test/newtours/";
WebDriver driver = new FirefoxDriver();
driver.get(baseUrl);
String innerText = driver.findElement(By
.xpath("//table[@width=\"270\"]/tbody/tr[4]/td"))
.getText();
System.out.println(innerText);
driver.quit();
}
Использование Inspect Element для доступа к таблицам в Selenium
Если получить номер или атрибут элемента крайне сложно или невозможно, то наиболее быстрым способом генерации XPath-кода является использование Inspect Element.
Рассмотрим приведенный ниже пример с домашней страницы Mercury Tours. Нам необходимо получить доступ к следующему тексту:

Шаг 1
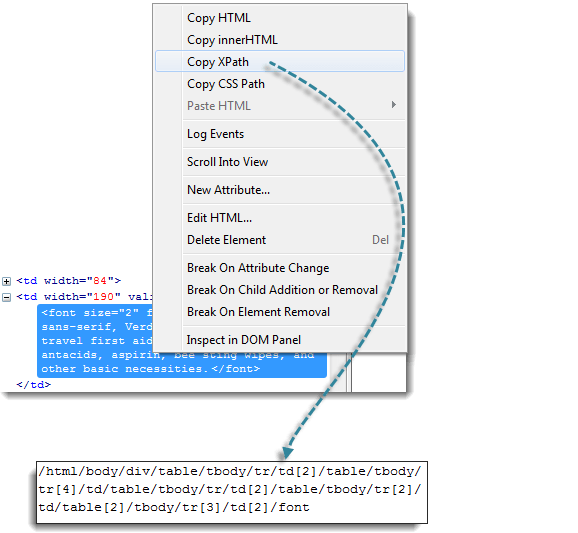
Для получения кода XPath используйте отладчик веб-приложений Firebug:
Шаг 2.
Найдите первый родительский элемент “table” и удалите все, что находится слева от него:

Шаг 3
Перед оставшейся частью кода поставьте двойную косую черту “//”, как мы делали ранее, и скопируйте её в код WebDriver. Обратите внимание, как изменится код при помещении его в метод By.xpath():

Приведенный ниже код WebDriver сможет успешно получить внутренний текст элемента, к которому мы обращаемся.
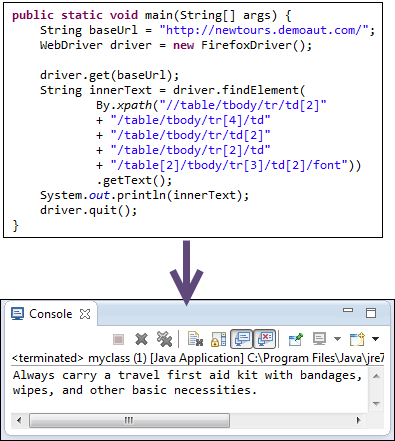
public static void main(String[] args) {
String baseUrl = "http://demo.guru99.com/test/newtours/";
WebDriver driver = new FirefoxDriver();
driver.get(baseUrl);
String innerText = driver.findElement(By
.xpath("//table/tbody/tr/td[2]"
+ "//table/tbody/tr[4]/td/"
+ "table/tbody/tr/td[2]/"
+ "table/tbody/tr[2]/td[1]/"
+ "table[2]/tbody/tr[3]/td[2]/font"))
.getText();
System.out.println(innerText);
driver.quit();
}
Резюме
- By.xpath() обычно используется для доступа к элементам веб-таблиц в Selenium.
- Если элемент написан глубоко в HTML-коде, так что определить число, используемое для предиката, очень сложно, мы можем использовать уникальный атрибут этого элемента.
- Атрибуты используются в качестве предикатов путем префиксации их символом @.
- Если получить номер или атрибут элемента крайне сложно или невозможно, используйте Inspect Element для генерации XPath-кода.
Перевод статьи «How to Handle Web Table in Selenium WebDriver».