
Идентификация гиперссылок на веб-странице в Selenium осуществляется по тексту ссылки. В этой статье мы рассмотрим доступные методы поиска и доступа к ссылкам с помощью WebDriver. Кроме того, разберем некоторые распространенные проблемы, возникающие при доступе к ссылкам, и способы их решения.
Примечание редакции: возможно, вас заинтересует статья “Как найти битые ссылки в Selenium”.
Содержание
- Поиск элементов по полному тексту ссылки
- Поиск элементов по части текста ссылки
- Как получить несколько ссылок с одинаковым текстом
- Чувствительность методов к регистру текста ссылки
- Ссылки снаружи и внутри блока
Друзья, поддержите нас вступлением в наш телеграм канал QaRocks. Там много туториалов, задач по автоматизации и книг по QA.
Поиск элементов по полному тексту ссылки
Доступ к ссылкам с использованием их точного текста осуществляется с помощью метода By.linkText(). Однако если имеются две ссылки с одинаковым текстом, этот метод получит доступ только к первой из них.
Рассмотрим приведенный ниже HTML-код:
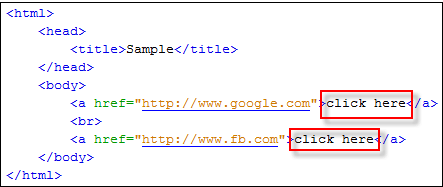
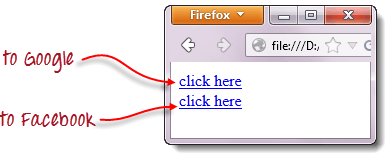
При запуске приведенного ниже кода WebDriver происходит переход по первой ссылке “click here”.
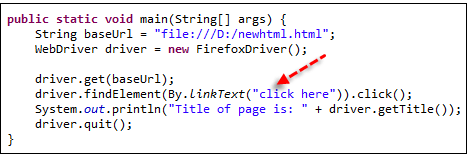
Код:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
public class MyClass {
public static void main(String[] args) {
String baseUrl = "http://demo.guru99.com/test/link.html";
System.setProperty("webdriver.chrome.driver","G:\\chromedriver.exe");
WebDriver driver = new ChromeDriver();
driver.get(baseUrl);
driver.findElement(By.linkText("click here")).click();
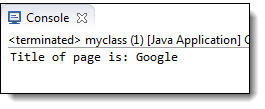
System.out.println("title of page is: " + driver.getTitle());
driver.quit();
}
}
Как это работает:
В строке driver.findElement(By.linkText("click here")).click(); findElement() находит ссылки на странице, а метод .click() служит для доступа к ним.
В результате происходит автоматический переход на страницу Google.
Поиск элементов по части текста ссылки
Доступ к ссылкам с использованием части их текста осуществляется с помощью метода By.partialLinkText(). Если указать частичный текст ссылки, который имеет несколько совпадений, то доступ будет осуществляться только к первому.
Рассмотрим приведенный ниже HTML-код:
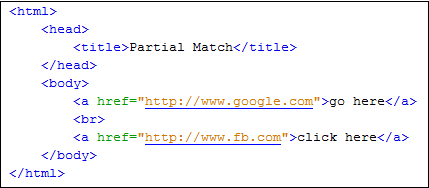
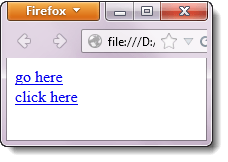
При выполнении приведенного ниже кода WebDriver по-прежнему будет осуществляться переход на сайт Google (эта ссылка встречается на странице первой).
Код:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
public class P1 {
public static void main(String[] args) {
String baseUrl = "http://demo.guru99.com/test/accessing-link.html";
System.setProperty("webdriver.chrome.driver","G:\\chromedriver.exe");
WebDriver driver = new ChromeDriver();
driver.get(baseUrl);
driver.findElement(By.partialLinkText("here")).click();
System.out.println("Title of page is: " + driver.getTitle());
driver.quit();
}
}
Как получить несколько ссылок с одинаковым текстом
Как же обойти описанную выше проблему? Если имеется несколько ссылок с одинаковым текстом и мы хотим получить доступ не только к первой, то как это сделать?
В таких случаях, как правило, используются различные локаторы, например, By.xpath(), By.cssSelector() или By.tagName().
Наиболее часто используется By.xpath(). Это самый надежный вариант, но он выглядит сложным и нечитаемым.
Чувствительность к регистру текста ссылки
Параметры для By.linkText() и By.partialLinkText() чувствительны к регистру. Например, на главной странице сайта компании Mercury Tours есть две ссылки, содержащие текст “egis”: одна из них – ссылка “REGISTER”, расположенная в верхнем меню, а другая – ссылка “Register here”, расположенная в правой нижней части страницы.
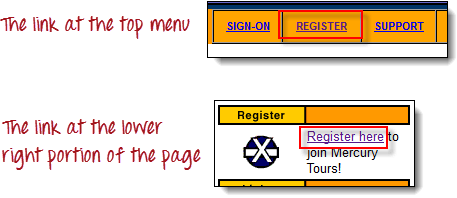
Хотя обе ссылки содержат последовательность символов “egis”, метод By.partialLinkText() будет обращаться к этим двум ссылкам по отдельности в зависимости от регистра символов.
Рассмотрим пример кода ниже:
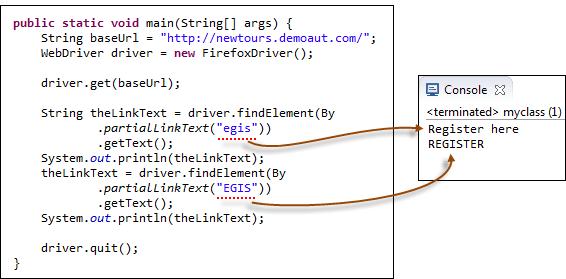
Код:
public static void main(String[] args) {
String baseUrl = "http://demo.guru99.com/test/newtours/";
System.setProperty("webdriver.chrome.driver","G:\\chromedriver.exe");
WebDriver driver = new ChromeDriver();
driver.get(baseUrl);
String theLinkText = driver.findElement(By
.partialLinkText("egis"))
.getText();
System.out.println(theLinkText);
theLinkText = driver.findElement(By
.partialLinkText("EGIS"))
.getText();
System.out.println(theLinkText);
driver.quit();
}
Ссылки снаружи и внутри блока
Последний стандарт HTML5 позволяет размещать теги <a> как внутри, так и снаружи блочных элементов <div>, <p>, или <h3>.
Методы By.linkText() и By.partialLinkText() позволяют получить доступ к ссылке, расположенной как внутри, так и снаружи этих блочных элементов.
Рассмотрим приведенный ниже HTML-код:

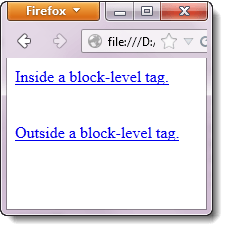
В приведенном ниже коде WebDriver доступ к обеим ссылкам осуществляется с помощью метода By.partialLinkText():
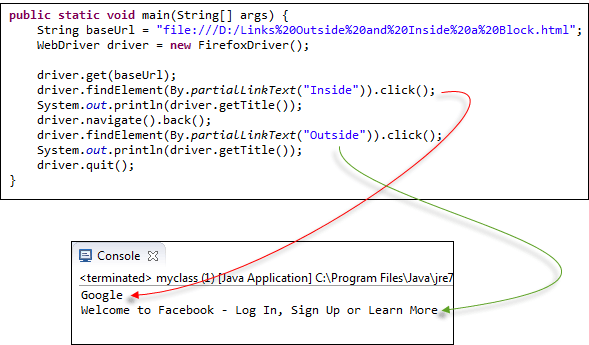
Код:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
public class MyClass {
public static void main(String[] args) {
String baseUrl = "http://demo.guru99.com/test/block.html";
System.setProperty("webdriver.chrome.driver","G:\\chromedriver.exe");
WebDriver driver = new ChromeDriver();
driver.get(baseUrl);
driver.findElement(By.partialLinkText("Inside")).click();
System.out.println(driver.getTitle());
driver.navigate().back();
driver.findElement(By.partialLinkText("Outside")).click();
System.out.println(driver.getTitle());
driver.quit();
}
}
Приведенный результат подтверждает, что доступ к обеим ссылкам был осуществлен успешно, поскольку заголовки соответствующих страниц были получены правильно.
Выводы
- Доступ к ссылкам осуществляется с помощью метода
click(). - Помимо локаторов, доступных для любого веб-элемента, для ссылок также есть локаторы, основанные на их тексте:
By.linkText()– определяет местоположение ссылок на основе точного совпадения текста, заданного в качестве параметра, с их текстомBy.partialLinkText()– определяет местоположение ссылок на основе совпадения текста, заданного в качестве параметра, с частью тескста ссылки
- Оба этих локатора чувствительны к регистру
- При наличии нескольких совпадений функции
By.linkText()иBy.partialLinkText()выбирают только первое совпадение. В случаях, когда имеется несколько ссылок с одинаковым текстом, используются другие локаторы, основанные на xpath или CSS - Методы
findElements()иBy.tagName("a")находят на странице все элементы, соответствующие критериям локатора. - С помощью функций
By.linkText()иBy.partialLinkText()можно находить ссылки независимо от того, находятся ли они внутри или снаружи элементов блочного уровня.
Перевод статьи «Locate Elements by Link Text & Partial Link Text in Selenium».
Пингбэк: Как кликнуть по ссылке-изображению в Selenium