Перевод статьи «Cypress for Dummies 3».
Начну с пояснения: данный шаблон проектирования уже давно является практически стандартным архитектурным шаблоном для множества работ по автоматизации. Мы все согласны с преимуществами, которые он дает. При этом мы иногда пренебрегаем некоторыми сложностями, которые он создает в долгосрочной перспективе.
Я думаю, мы ценим более современные подходы потому, что уже знакомы с объектной моделью Page Object Model (сокращенно POM) и реализовывали ее достаточно много раз, чтобы осознать ее недостатки. В этой статье я постараюсь объяснить важные части POM, которые мы реализуем.
По моему мнению, любой QA, начинающий свой путь в автоматизации, должен знать об этом паттерне. Так что я рекомендую вам изучить его и то, как он используется в различных фреймворках, таких как Selenium.
Еще одна оговорка: считается, что страничные объекты используются в объектно-ориентированном программировании, отсюда и пошло их название. В Cypress мы будем использовать функциональное программирование, поэтому применим некоторые концепции для POM, адаптированные для ФП.
Я не буду углубляться в детали, поскольку хочу, чтобы эта статья была короткой и практичной. Лучше рассмотрим преимущества POM.
Преимущества POM
- Улучшение читаемости и сопровождения. POM отделяет структуру и макет страницы от тестовых сценариев, что делает код более читаемым и простым в сопровождении. Изменения в пользовательском интерфейсе можно вносить в одном месте, а не в каждом тесте, что также упрощает сопровождение.
- Возможность повторного использования кода. Классы страниц могут быть переиспользованы в нескольких тестовых сценариях, что позволяет сократить дублирование кода. Это не только экономит время, но и снижает вероятность ошибок.
- Уменьшение количества модификаций скриптов. Изменения пользовательского интерфейса требуют обновления только объектов страницы, а не тест-кейсов. По этой причине уменьшается необходимость модифицировать тестовые скрипты при изменении UI, что приводит к более стабильному набору тестов.
- Модульность. Данная модель поощряет модульный подход к разработке тестовых сценариев. Создавая модульные тест-кейсы, тестировщики могут строить более масштабируемые и понятные тестовые сценарии.
- Повышение качества совместной работы. POM приводит к созданию более организованного и понятного кода. Поэтому командам, особенно таким, в которых работает несколько инженеров по автоматизации, легче сотрудничать при разработке тестовых сценариев.
- Упрощение поиска и устранения неисправностей. При четком разделении структуры страницы и тестов становится проще определить, где кроются проблемы – в логике тестового сценария или в реализации объекта страницы.
- Интеграция с другими инструментами. POM хорошо работает со многими инструментами тестирования и фреймворками, что делает ее применение универсальным подходом, позволяющим интегрироваться в различные экосистемы тестирования.
БЕСПЛАТНО СКАЧАТЬ КНИГИ в телеграм канале "Библиотека тестировщика"
Реализация POM
Реализация POM проста. Но, как всегда, когда дело доходит до написания кода, нужно быть последовательным. Основная идея – в разделении автоматизации функций по разным слоям (отдельным каталогам), а также по разным файлам на основе страниц AUT. AUT расшифровывается как Application Under Testing – “тестируемое приложение”.
Базовыми слоями являются:
- Объекты страницы. Они предназначены для группировки всех элементов страницы из нашего AUT.
- Определения шагов. Они предназначены для группировки всех функций для взаимодействия со страницей из нашего AUT.
К дополнительным слоям относятся:
- Фичи (если вы реализовали какую-либо форму gherkin).
- Утилиты (вы можете использовать эти файлы, если создаете сложную логику, которая может переиспользоваться).
Шаг 1. Создание файлов страниц
(В проекте объектно-ориентированного программирования это будут классы).
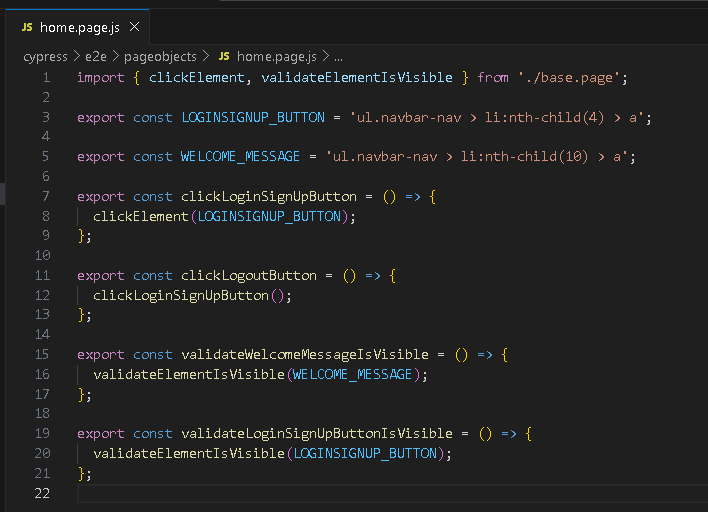
Начнем со страничных объектов, которые представляют собой файлы, определяющие сам шаблон POM. Их назначение – содержать элементы, с которыми вы будете взаимодействовать на каждой странице вашего приложения. Возвращаясь к примеру, для реализации нашего теста нам потребуется 2 страницы.
Я создам файлы home.page.js и login.page.js, но для начала нам нужно место для их хранения. В моем примере это каталог pageobjects.

Шаг 2. Определение элементов страницы
Теперь, когда у нас есть страницы, необходимо определить, с какими элементами на них мы будем взаимодействовать.
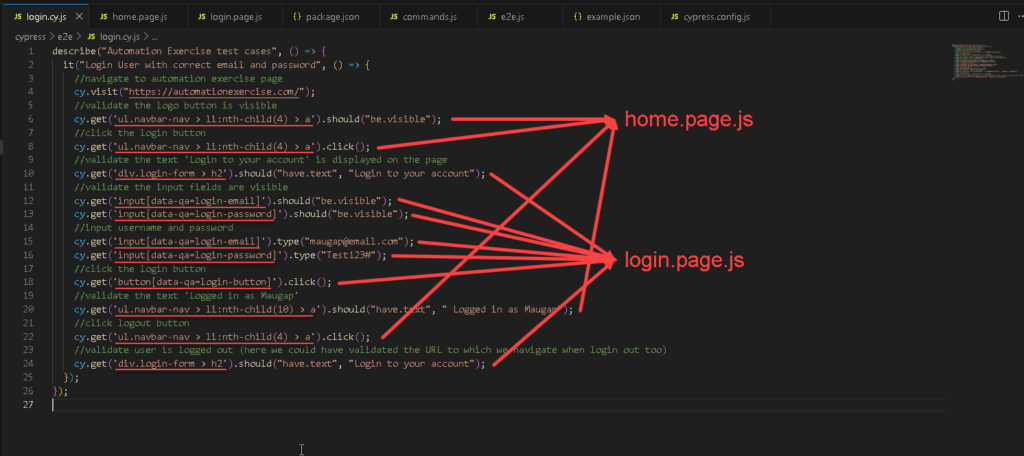
Мы создаем эти элементы как константы в соответствующем файле. Как вы понимаете, некоторые селекторы повторяются. Чтобы иметь возможность их переиспользовать и в случае изменения любого из них вносить обновления только в одном месте, мы можем создать константы для каждого элемента в соответствующем файле. Т.е., если изменится ID селектора кнопки входа в систему, то нам нужно будет изменить его только в объекте страницы, и тест продолжит работать должным образом.

Теперь я заменю селекторы их строками, и вы увидите, как код станет более читабельным.
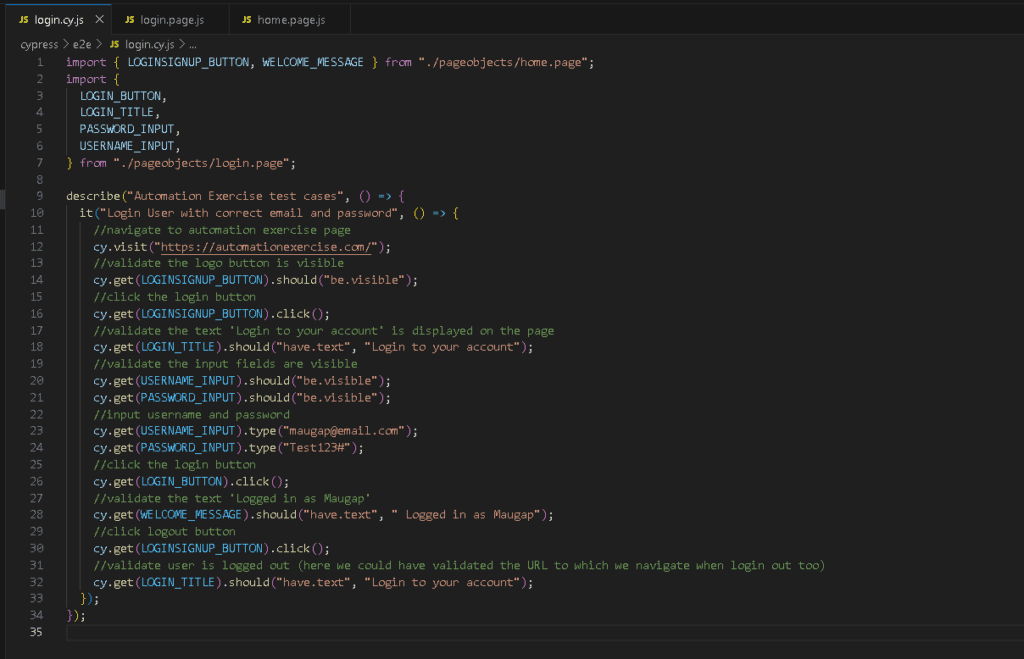
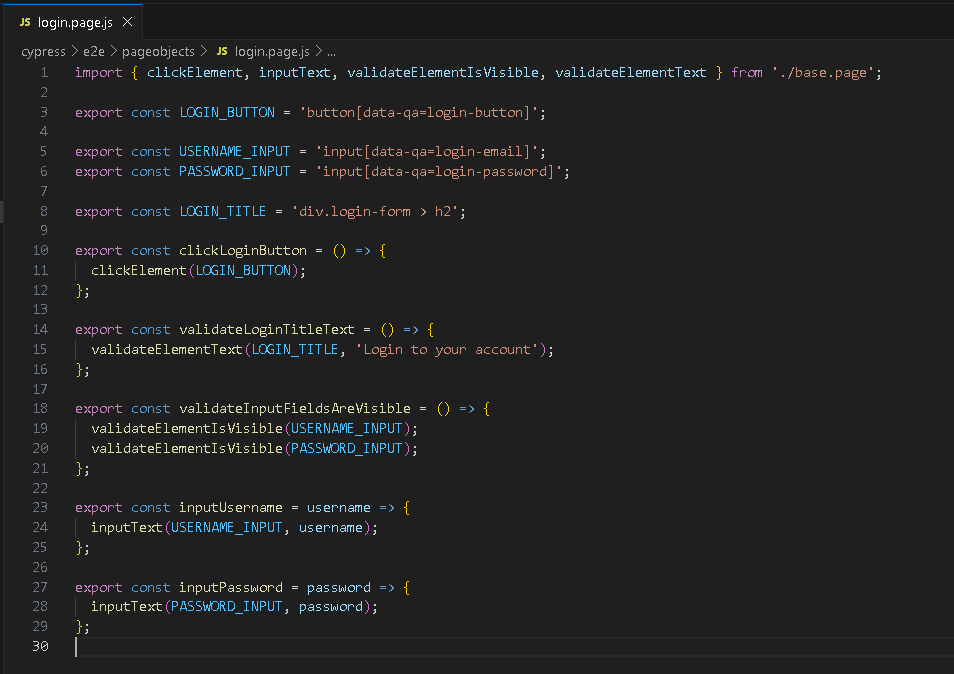
Шаг 3. Реализация функций высшего порядка
Теперь мы создадим высокоуровневые функции, которые можно использовать для обработки некоторых взаимодействий с нашими страницами. Я начну с создания базовой страницы. В ООП мы использовали этот шаблон для обработки общей логики для всех страниц.
Я просто буду использовать его для хранения некоторых полезных функций, которые помогут мне упростить взаимодействие со страницами. Например – для щелчков по элементам и ввода текста в поля.
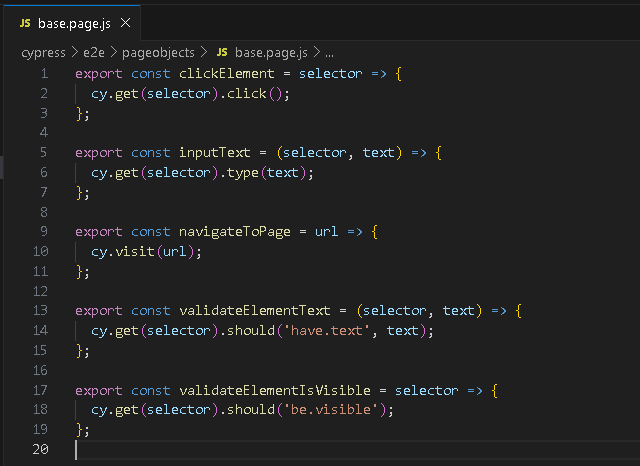
В рамках реализации функций мы можем также реализовать базовое взаимодействие элементов на страницах.
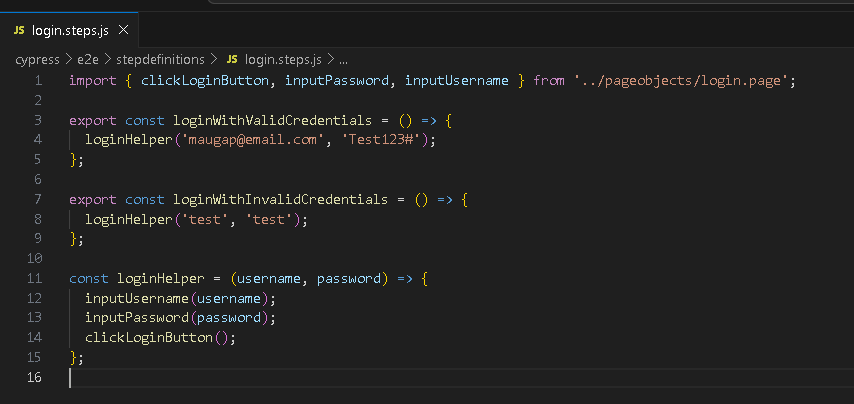
Шаг 4. Реализация определений шагов
Допустим, у нас есть несколько шагов с более сложной логикой. Или мы обнаружили, что некоторые функции, которые нам нужно выполнить, в дальнейшем можно переиспользовать или перепрофилировать с другой логикой.
В этом случае мы можем реализовать уровень определений шагов, в котором будем вызывать функции со страниц. Здесь, чтобы проиллюстрировать эту практику, я привел простой пример с логикой входа в систему.
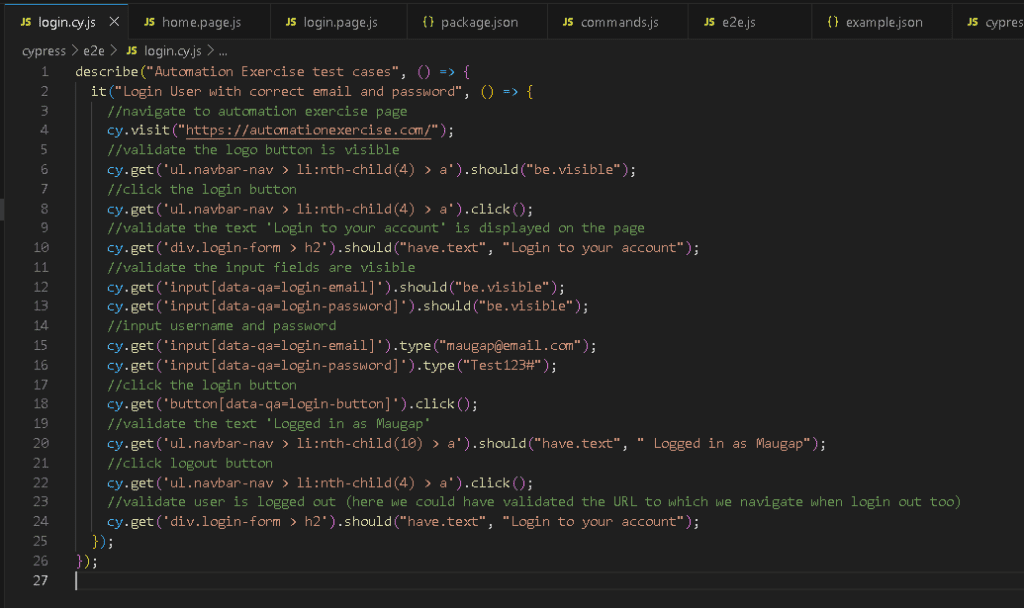
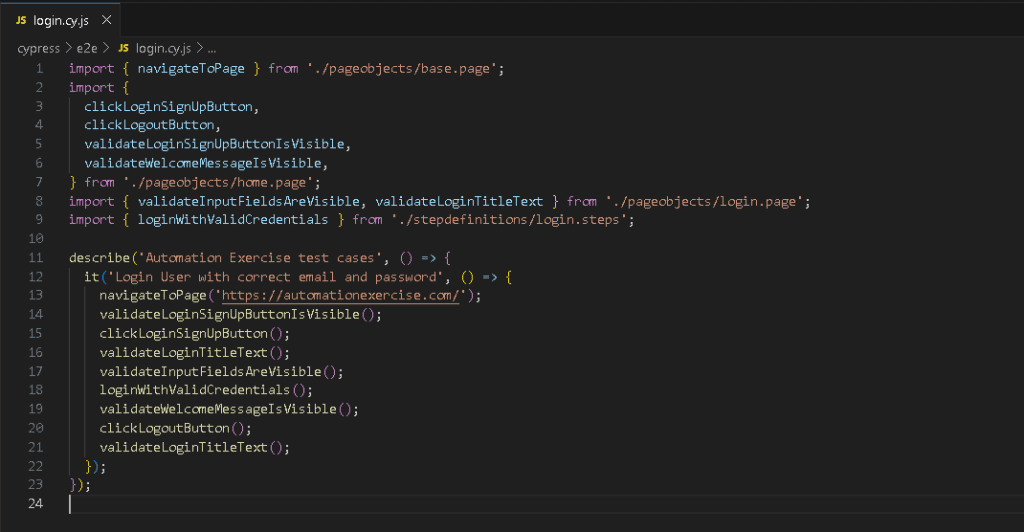
Заключение
Единственное, на что я бы рекомендовал обратить внимание, – это правильный нейминг. Когда имена функций и переменных представляют части приложения, это помогает легко определять места поломок и сокращать время, необходимое для отладки и исправления тестов.
Среди других практик – именование страниц и файлов шагов на основе того же имени, которое команда дала странице AUT. Например, login. У нас есть файл login.page.js и login.steps.js.
Еще одна вещь, которую вы можете рассмотреть, это перемещение ваших тестов в одну директорию, в которой вы можете лучше их организовать. Например, в папку feature.