
Перевод статьи «How to structure a big project in Cypress».
Cypress предоставляет определенную структуру проекта, но по мере роста проекта появляется необходимость в различных дополнительных файлах.
В этой статье я бы хотел поделиться своим взглядом на то, как должен создаваться и структурироваться успешный проект, основываясь на своем почти 7-летнем опыте создания различных проектов на Cypress.
Содержание:
- Основы и принципы
- BDD без Cucumber
- Arrange, Act, Assert
- Аннотации к тестам
- Spec-файлы
- Селекторы
- Пользовательские команды
- TypeScript
- Покрытие кода
- Утилиты
- Глобальные хуки
- Теги для тестов
- Переключение конфигурации
- Node scripts
- Документация
- Вывод
Подпишитесь на наш ТЕЛЕГРАМ КАНАЛ ПО АВТОМАТИЗАЦИИ ТЕСТИРОВАНИЯ
Основы и принципы
Прежде всего, давайте поговорим о некоторых принципах, которые помогали мне принимать решения в моих предыдущих проектах и были важны для их успеха.
Итак, вот эти принципы:
Автоматизация тестирования должна быть частью репозитория с исходным кодом. Недавно я проводил опрос на LinkedIn и выяснил, что 45% тех, кто прошел опрос, не размещают свои тесты в одном и том же репозитории с исходным кодом. На мой взгляд, код автоматизации тестирования (и особенно при использовании Cypress) не должен быть отделен от исходного кода тестируемого приложения. Это позволяет синхронизировать все тесты и все ветки с разработкой, облегчает непрерывную доставку.
Читабельность тестов. Неудачный тест может быть недостаточным для определения того, что именно пошло не так. Тестировщики – это поставщики информации. Это означает, что если неудачный тест не дает достаточной информации о том, что произошло или почему это произошло, то тестировщик плохо справился со своей работой.
Тестирование должно повышать скорость релиза продукта. Нашим пользователям важно не то, насколько красочны наши тесты, а то, какую пользу несет им продукт. Для успешной компании важно приносить эту пользу и делать это быстро. Это означает, что тестирование должно начинаться как можно раньше, а автоматизация тестирования должна быть как можно более эффективной и быстрой.
Время человека дороже времени машин. Важно убедиться, действительно ли создание средств автоматизации тестирования сэкономит ваше время. Все, что вы создадите, будет нуждаться в обслуживании, и об этом важно подумать, особенно при выборе между созданием инструмента или оплатой за готовое решение.
BDD без Cucumber
Тесты, которые я пишу, отражают определенное поведение или описывают, как используется та или иная функция приложения. Когда я начинал заниматься автоматизацией тестирования, мы с коллегой записывали 15 наиболее важных тестовых сценариев для приложения и соревновались друг с другом, кто быстрее их выполнит (она – вручную, или я с помощью автоматизированного тестирования).
Мы так и не решились перейти на синтаксис Gherkin или фреймворк Cucumber. Простота команд Cypress была для нас достаточно хорошим решением и позволяла понять, что делает тест.
Я нашел этот твит от Kent C. Dodds:
The more your tests resemble the way your software is used, the more confidence they can give you.- Кент К. Доддс ? (@kentcdodds) 23 марта 2018 года.
Это означает, что мы должны стремиться к тому, чтобы наши тесты следовали определенным сценариям, которые мы затем объединяли в группы в соответствии с их функциональными особенностями. Результат такой структуры тестов выглядит примерно так:
cypress/ |-- e2e/ | |-- board/ | `-- list/ |-- fixtures/ `-- support/
Папки представляют определенную функцию приложения, а файлы спецификаций внутри этих папок – поведение или пользовательскую историю (user story), о которой пойдет речь в тестовом сценарии. Как уже было сказано, эти сценарии представляют реальное поведение пользователя, но они не написаны на синтаксисе Gherkin (Given, When, Then) или с использованием фреймворка Cucumber. Хотя сообщество разработчиков Cypress создало preprocessor Cucumber, который позволяет писать тесты подобным образом, я предпочитаю избегать этого решения.
На мой взгляд, это добавляет ненужный слой между тестовым кодом и приложением, а также замедляет создание тестов и добавляет ненужное обслуживание.
Arrange, Act, Assert
Вместо подхода “Given-When-Then” я предпочитаю использовать подход “Arrange-Act-Assert“. Они очень похожи по своей сути, но мне кажется, что второй подход чётче определяет цель тестирования. Ключевое слово “When” в синтаксисе Gherkin кажется несколько двусмысленным, поскольку не всегда понятно, относится оно к действию или к состоянию. В шаблоне “Arrange-Act-Assert” это выражено более четко.
before( () => {
// arrange
cy.request('POST', '/api/lists', { name: 'new list' })
})
it('creates an item', () => {
// act
cy.visit('/')
cy.get('#create').type('list item{enter}')
// assert
cy.get('[data-cy=item]').should('be.visible')
})
Обычно часть “Arrange” происходит через вызовы API, настройку базы данных и редко через пользовательский интерфейс. Чаще всего этот шаг выполняется в before() или beforeEach().
Когда сложно решить, следует выполнять какую-то часть теста через пользовательский интерфейс (UI) или через API, паттерн “Arrange-Act-Assert” помогает принять решение. Все, что выполняется через UI, относится к шагу “Act”. Все, что делается до этого, входит в часть “Arrange” и не делается через UI.
Шаги “Act” и “Assert” могут повторяться несколько раз в процессе сквозного тестирования.
Аннотации к тестам
Как уже говорилось вначале, очень важна читабельность тестов. Она помогает упростить навигацию по ним. При написании блока it() название теста должно давать достаточно информации о том, что представляет собой тестовый сценарий.
Bad practice:
it('board is visible', () => {})
it('works in edge cases', () => {})
it('handles input', () => {})
Best practice:
it('creates a board and navigates to board detail', () => {})
it('throws error when trying to access private board', () => {})
it('shows a warning message when input is empty', () => {})
В идеале название теста нужно писать так, чтобы по нему можно было понять, что делает тест, не заглядывая в его содержание.
Однажды мой коллега посоветовал, чтобы it и название теста читались как предложение. Мне такой подход очень понравился, хотя встречались ситуации, когда названия тестов получались довольно странными.
Не усложняйте ситуацию, если нужно нарушить какое-то правило, нарушьте его.
Еще один полезный способ сделать тесты более читабельными – добавить свои собственные логи.
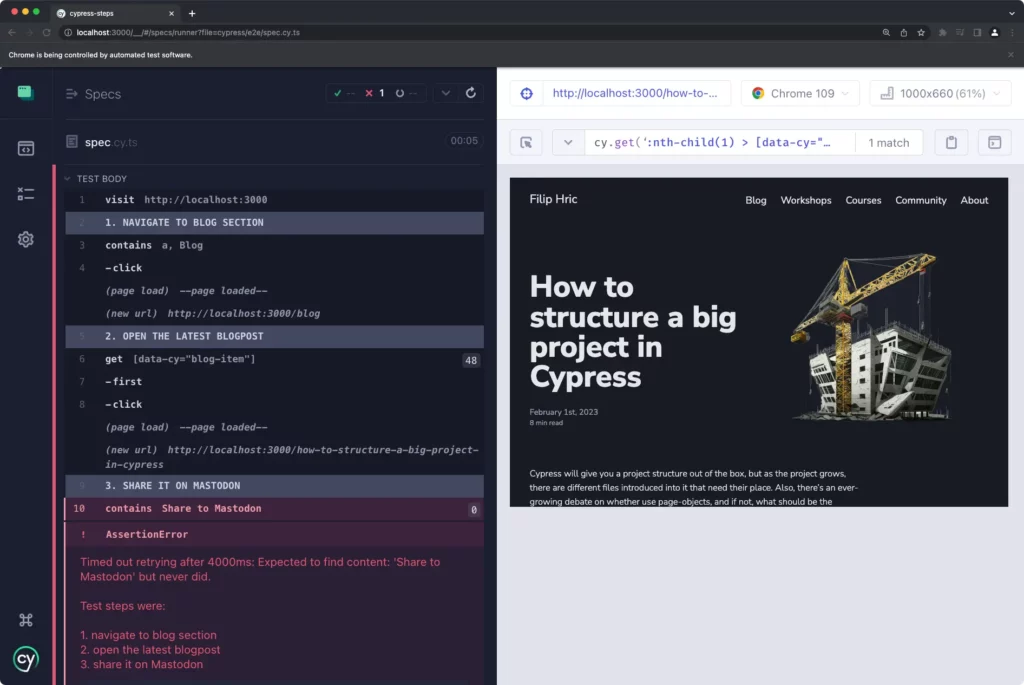
Я создал плагин который делает следующее:
- Каждая команда
cy.step()описывает шаг в тесте. - Каждая команда
cy.step()автоматически нумеруется. - При неудачном выполнении теста к сообщению об ошибке добавляется пронумерованный список.
- В терминал выводится сообщение об ошибке и скриншот со сбоем.
Spec-файлы
Каждый spec-файл должен содержать всего несколько тестов. End to end тесты, как правило, длиннее, и поэтому требуется работа с большим количеством строк кода. Если в spec-файле появляется несколько длинных сценариев, в нем становится трудно ориентироваться.
Блоки describe() помогают сгруппировать тесты, имеющие что-то общее. Чаще всего это хуки before() или beforeEach(). Таким образом, в случаях, когда мне нужно разделить тесты на группы, я обычно делаю это с помощью новой спецификации (spec) вместо нового блока describe().
Однако при попытке “Run all specs” в открытом режиме (open mode) в Cypress возникает проблема. В этом режиме, по сути, создается одна спецификация из нескольких файлов, что означает, что все ваши before() и beforeEach() хуки будут конкатенированы, что приведет к неожиданным результатам. Об этом следует помнить. Однако при работе над большим проектом я практически никогда не запускаю все спецификации в открытом режиме.
Селекторы
В прошлом я пробовал разные подходы, но в итоге остановился на рекомендации Cypress и добавил селекторы data-cy в приложение. Такой подход оказался наиболее стабильным. Полагаться на имена классов часто приводит к случайным сбоям. Это особенно актуально в наши дни, поскольку разработчики часто используют такие библиотеки пользовательского интерфейса, как Material Design или Bootstrap. Обновления этих библиотек могут часто приводить к изменению классов, что ломает наши тесты.
Добавление собственных атрибутов
Добавление собственных атрибутов данных для селекторов может помочь вам узнать больше о тестируемом приложении. Давайте рассмотрим это на простом примере:
Представьте, что у вас есть кнопка, которая выглядит следующим образом:
<button disabled> <span>Click me!</span> </button>
В своем тесте вы хотите выполнить клик по кнопке. Обратите внимание, что кнопка имеет свойство disabled, что означает, что пользователю не удастся выполнить клик по ней.
// this will pass, but click will do nothing
cy.get('span').click()
// this will fail, because button is disabled
cy.get('button').click()
Поэтому выбор правильного селектора очень важен.
Я бы также посоветовал добавлять свои data-* атрибуты самостоятельно, даже если вы не являетесь разработчиком приложения. Таким образом, вы лучше поймете структуру приложения, а также познакомитесь с различными фреймворками.
Устранение дублирования, улучшение читабельности
Еще одним преимуществом добавления собственных атрибутов в исходный код является устранение дублирования, возникающего при использовании объектов страницы. То же самое можно сказать и о хранении элементов в отдельном файле. Это ещё один аспект, о котором нужно заботиться, так как легко может возникнуть расхождение между реальным состоянием приложения и тестами.
Добавление data-* селекторов также может помочь вам улучшить читабельность ваших тестов. Некоторые люди, с которыми я общаюсь, беспокоятся по поводу naming convention, но я бы не стал переживать по этому поводу. Наличие двух одинаковых data-* атрибутов не является проблемой, пока они не встречаются в одном и том же тесте или на одном и том же экране. Я бы определенно посоветовал ориентироваться на реальный интерфейс и визуальное взаимодействие пользователя с приложением при создании селекторов.
// ❌ too complicated in my opinion
cy.get('[data-cy=account-screen-sidemenu-settings-modal]')
// ✅ much better
cy.get('[data-cy=settings-modal]')
Пользовательские команды
Пользовательские команды – одна из самых мощных возможностей Cypress. Возможность расширения библиотеки делает экосистему Cypress исключительно универсальной. Обычно я использую три категории пользовательских команд:
- служебные команды
- Вызовы API
- последовательности действий
Вызовы API
Используя Cypress, вы часто будете обращаться к API для настройки данных или выполнения какого-либо действия в вашем приложении. Поскольку не всегда хочется вызывать cy.request() и предоставлять необходимую авторизацию, заголовки или тело запроса, создание пользовательской команды – отличное решение. Можно создать функцию, которая будет принимать значения по дефолту или же можно передавать различные аргументы. Данные, полученные в результате вызова API, могут быть использованы в дальнейшем в тесте.
Служебные команды
Если вы используете data-* селекторы, то создание cy.getByDataCy() команды может оказаться полезным. Служебные команды обычно применяются для решения каких-то конкретных задач в приложении, например, команды cy.getClipboard(), cy.getTooltip() и т.д.
Последовательность действий
Последовательность действий (Action sequences) – это сценарии или наборы шагов, которые выполняются в тестировании веб-приложений.
Важно отметить, что action sequences представляют собой реальные пользовательские действия и взаимодействие с приложением, их нельзя полностью заменить вызовами API (программным интерфейсом приложения).
Например:
Cypress.Commands.add('pickSidebarItem', (item: 'Settings' | 'Account' | 'My profile' | 'Log out') => {
cy.get('[data-cy=hamburger-menu]')
.click()
cy.contains('[data-cy=side-menu]', item)
.click()
})
Организация пользовательских команд
Я следую такому правилу, которое заключается в том, чтобы поместить каждую пользовательскую команду в отдельный файл и добавить их все в отдельную папку в проекте Cypress:
big-project/ |-- cypress/ | |-- commands/ | |-- e2e/ | |-- fixtures/ | `-- support/ |-- .gitignore `-- cypress.config.ts
Папка commands может содержать категории пользовательских команд, но я не придерживаюсь этого правила. Поскольку пользовательские команды обычно имеют свое собственное уникальное имя, нет никакого смысла создавать отдельные папки.
Каждая команда находится в отдельном файле. Пример такой команды выглядит следующим образом:
declare global {
namespace Cypress {
interface Chainable {
addBoardApi: typeof addBoardApi;
}
}
}
/**
* Creates a new board using the API
* @param name name of the board
* @example
* cy.addBoardApi('new board')
*
*/
export const addBoardApi = function(this: any, name: string): Cypress.Chainable<any> {
return cy
.request('POST', '/api/boards', { name })
.its('body', { log: false }).as('board');
};
Документация Cypress рекомендует создавать центральный index.d.ts файл, содержащий определения типов для всех команд. Лично я больше склоняюсь к приведенному выше варианту, поскольку так создается меньше путаницы.
Каждая команда имеет свой собственный комментарий JSDoc, содержащий дополнительную информацию о команде. Это невероятно полезно для новичков. Кроме того, это позволяет поддерживать самодокументируемость кода.
Вместо того, чтобы использовать Cypress.Commands API, каждая команда записывается в виде функции, а затем импортируется в cypress/support/e2e.ts файл.
import { addBoardApi } from '../commands/addBoardApi'
Cypress.Commands.addAll({ addBoardApi })
Другой подход, который я обычно использую, заключается в том, чтобы создать index.ts файл, который добавляет все imports из папки cypress/commands в cypress/support/e2e.ts. Это удобно, если вы решили перенести свое приложение в монорепозиторий и добавить пользовательские команды в отдельную библиотеку, чтобы их можно было повторно использовать во всех проектах.
monorepo-project/ |-- node_modules/ |-- packages/ | |-- commands/ // library | |-- trelloapp/ // app | `-- trelloapp-e2e/ // tests |-- tools/ |-- .editorconfig |-- .eslintrc.json |-- .gitignore |-- .prettierignore |-- .prettierrc |-- nx.json |-- package-lock.json `-- package.jso
TypeScript
Во всех моих проектах используется TypeScript. Внедрить TypeScript в существующий JS-проект очень просто.
TypeScript очень хорошо работает с пользовательскими командами. Одним из способов использования TypeScript является повторное использование типов (интерфейсы, классы или пользовательские типы данных) из исходного кода в тестах:
import Board from '@/src/models'
cy.request<Board>('POST', '/api/boards', { name: 'new board' })
В приведенном примере кода показана команда cy.request(), которая будет возвращать типы данных из Board интерфейса, импортированного из исходного кода. Это означает, что если у вас есть интерфейс, подобный этому:
interface Board {
id: number;
starred: boolean;
name: string;
created: string;
user: number;
}
export default Board;
то вы сможете обнаружить ошибку, если решите написать тест для чего-то, что не является частью Board интерфейса.
import Board from '@/src/models'
cy.request<Board>('POST', '/api/boards', { name: 'new board' })
.then(({ body }) => {
// the "key" will be underlined in editor
expect(body.key).to.be.a('number')
})
Помимо проверки кода в редакторе, можно настроить проверку lint, которая позволит убедиться в отсутствии ошибок в коде:
"scripts": {
"lint": "tsc --noEmit"
}
Запуск команды npm run lint гарантирует, что любые ошибки в TypeScript, внесенные последними изменениями, будут обнаружены на ранних этапах. Вы можете настроить этот шаг проверки как pre-commit hook. Проверка занимает всего несколько секунд.
Однако самое большое преимущество заключается в том, что это создает двустороннюю синхронизацию между исходным кодом и вашими тестами. Это обеспечивает правильность ваших тестов, а также гарантирует, что изменения в исходном коде будут также отражаться на ваших тестах.
Приятным бонусом в TypeScript является возможность определения путей. Это устраняет проблему относительных путей в вашем проекте. Допустим, у вас есть путь, определенный в вашем файле tsconfig.json:
{
"compilerOptions": {
"target": "es5",
"lib": ["es5", "dom"],
"types": ["cypress","node"],
"baseUrl": "./",
"paths": {
"@fixtures/*": [
"cypress/fixtures/*"
]
},
"resolveJsonModule": true,
}
}
Импортировать fixture file в тест можно следующим образом:
import boardSchema from '@fixtures/boardSchema.json'
it('board returns proper JSON schema', () => {
cy.api({
url: `/api/boards/1`
}).its('body')
.should('jsonSchema', boardSchema)
})
Покрытие кода
Зачастую можно встретить команды тестирования, которые стремятся к 100%-ному покрытию кода, но я не считаю это особенно полезным. Отчет о покрытии кода может выступать в роли карты, показывая структуру приложения и указывая на места, которые еще не были протестированы.
Обычно, в первую очередь, рассматриваются бизнес-кейсы, но существует множество крайних случаев, о которых часто забывают, и которые могут привести к разочарованию наших пользователей. Покрытие кода помогает найти такие области.
Отчеты о покрытии кода можно сохранять в виде артефактов, а можно использовать сервис типа Codecov, который предоставляет красочные аналитические данные о покрытии вашего кода.
Утилиты
Каждый проект специфичен и имеет ряд общих проблем, которые необходимо решить. Чтобы не решать одну и ту же проблему несколько раз, я помещаю все свои утилиты в папку cypress/utils. Это могут быть такие утилиты, как generateRandomUser(), getAuthorization() и другие. Обычно я импортирую их прямо в тест, вместо того, чтобы включать в support file. В общем их не так много, поскольку Cypress включает в себя библиотеку lodash, в которой много полезных утилит.
// imports lodash from Cypress
const { _ } = Cypress
// generates number between 0 and 10
const randomNumber = _.random(10)
Глобальные хуки
В моих проектах обычно настраивается несколько глобальных хуков. Обычный сценарий их использования заключается в обработке сообщения о согласии на использование файлов cookie. Добавление глобального хука beforeEach() может настроить все важные файлы cookie и предотвратить отображение сообщения в ваших тестах.
beforeEach(() => {
cy.setCookie('user_consents', '{"marketing":false,"essential":true}')
})
Вы всегда можете использовать команду cy.clearCookies() для удаления cookies в тесте, проверяющем сообщение о согласии на использование cookies.
Теги для тестов
Как только проект начинает расти, становится практически невозможным запускать все тесты при каждом коммите. Разделить тесты на категории можно с помощью плагина @cypress/grep. Он позволяет запускать тесты на основе их названия или тега.
Прежде всего, создается категория @smoke, которая заботится о наиболее важных сценариях тестирования. Категория тестов @smoke может находиться в отдельной папке, но лично я предпочитаю, чтобы тесты находились в папках, соответствующих конкретным функциональностям приложения.
it('creates a new board', { tags: ['@smoke'] }, () => {
// test
})
Один тест может содержать несколько тегов, что позволяет запускать его на основе определенной цели тестирования. Например, тег @email – для запуска всех тестов, использующих валидацию электронной почты, @mobile – для всех мобильных тестов, или @visual – для всех тестов, содержащих визуальные валидации.
В CLI (Command Line Interface) эти тесты могут быть запущены следующей командой:
npx cypress run --env grepTags='@smoke'
Переключение конфигурации
Важно, чтобы тест работал в различных окружениях. Чтобы упростить эту задачу, я обычно создаю папку config, которая содержит .json файлы со всеми переменными, специфичными для окружения, такими как baseUrl, url API или другой информацией, которая может использоваться во время тестирования. Они передаются в объект env из .json файла и могут быть легко доступны с помощью Cypress.env().
Следующая настройка гарантирует, что необходимая информация будет добавлена в проект:
import { defineConfig } from 'cypress'
export default defineConfig({
// other config attributes
setupNodeEvents(on, config) {
// if version not defined, use local
const version = config.env.version || 'local'
// load env from json
config.env = require(`./cypress/config/${version}.json`);
// change baseUrl
config.baseUrl = config.env.baseUrl
return config
}
})
При выполнении теста с другой конфигурацией достаточно запустить тест, подобный этому:
npx cypress open --env version="production"
и Cypress загрузит все необходимые переменные.
Помимо того, что конфигурация задается в отдельном .json файле, существует информация, которую не следует коммитить в репозитории, например, пароли, api ключи и т.д. .
Для облегчения работы я использую пакет dotenv который берет на себя управление переменными env с помощью .env файла.
ADMIN_KEY="1234-5678-abcd-efgh"
⚠️ Всегда следите за тем, чтобы
.envфайл был добавлен в.gitignoreиначе вы рискуете выложить конфиденциальную информацию в открытый доступ.
Для загрузки ключей необходимо импортировать пакет dotenv в cypress.config.ts, чтобы переменные env были загружены в Cypress и могли быть использованы во время тестирования:
import { defineConfig } from 'cypress'
import 'dotenv/config'
export default defineConfig({
// other config attributes
setupNodeEvents(on, config) {
// read ADMIN_KEY from .env file
config.env.ADMIN_KEY = process.env.ADMIN_KEY
return config
}
})
Node scripts
Файл cypress.config.ts может становиться слишком большим, особенно при настройке задач или решении вопросов с конфигурацией. Поэтому я начал разбивать их на отдельные файлы и добавлять в папку scripts.
scripts/ |-- codeCoverage.ts `-- resolveGoogleVars.ts
Таким образом, основной файл конфигурации остается чистым и легко читаемым. Это также облегчает поддержку нескольких cy.task() команд.
Документация
Каждый раз, когда новичок присоединяется к команде, он может либо замедлить ее работу, либо сделать ее более эффективной. Именно поэтому наличие хорошей документации важно.
Обычно документация состоит из трех важных частей:
- установка проекта
- пояснения, рекомендации, примеры
- правила для pull requests
Документация по установке должна содержать всю необходимую информацию для установки и запуска проекта. Это будет документ, который постоянно обновляется, так как изменения, внесенные в репозиторий, должны отражаться в нем.
Поскольку каждый проект имеет свои особенности, важно их объяснить. Какие соглашения существуют в проекте? Как решаются общие проблемы? Какие соглашения используются в данном репозитории? На все эти вопросы следует давать ответы в документации. Главная цель этого документа – облегчить вам жизнь, поэтому будет хорошо, если он будет легким для чтения и, при необходимости, разбит на несколько файлов.
Я также считаю полезным установить некоторые основные правила для пул-реквестов.
cypress/
|-- commands/
|-- config/
`-- docs/
|-- best-practices.md
`-- installation.md
Вывод
Большие проекты редко сводятся к простому использованию команд Cypress, они имеют гораздо большее отношение к проектированию самих тестов и общей структуре проекта. Большинство моих проектов – это живые организмы, которые меняются и развиваются по мере того, как меняются время и потребности. Моя текущая структура проекта выглядит примерно так:
big-project/ |-- cypress/ | |-- commands/ | |-- config/ | |-- docs/ | |-- downloads/ | |-- e2e/ | |-- fixtures/ | |-- screenshots/ | |-- scripts/ | |-- support/ | |-- utils/ | `-- videos/ `-- cypress.config.ts